Zum Download des Programms
| « Selektion in Linked Views | Mahalanobis und robuste Distanz » |
k means Clustering
Beim k means Clustering-Algorithmus werden k zufällig gewählte Datenpunkte
als Start für die Clusterzentren gewählt.
Anschließend wird jeder Datenpunkt jenem Cluster zugeordnet, dessen Clusterzentrum den kleinsten Abstand aufweist.
Neue Clusterzentren werden berechnet, in dem die Datenpunkte eines Clusters gemittelt werden. Die Zuordnung
der Datenpunkte und die Neuberechnung der Clusterzentren wird mehrmals wiederholt, bis sich die Clusterzentren
nicht mehr bzw. nur geringfügig ändern oder bis eine maximale Iterationszahl erreicht ist.
Für das Clustering können folgende Einstellungen vorgenommen werden:
- Anzahl der Cluster (k)
- Anzahl der maximalen Iterationen
- Minimale Updateschranke (Wenn kein Clusterzentrum ein Update erfährt, das diese Schranke übertrifft, wird der Clusterprozess gestoppt.)
- Auswahl und Gewichtung der Dimensionen nach denen geclustert werden soll.
Es können sowohl die Clusterzugehörigkeiten als auch die Distanzen der Datenpunkte zu ihrem Clusterzentrum abgespeichert werden. In dem folgenden Beispiel wurde ein Clustering für den Iris-Datensatz durchgeführt. Dieser Datensatz enthält vier verschiedene Messungen aufgrund deren man versucht, drei verschiedene Arten von Iris-Blumen zu unterscheiden. (Eine ausführliche Beschreibung kann hier nachgelesen werden.) Das k means Clustering wurde nun auf diesen vier Messdimensionen durchgeführt. Drei Cluster wurden generiert.
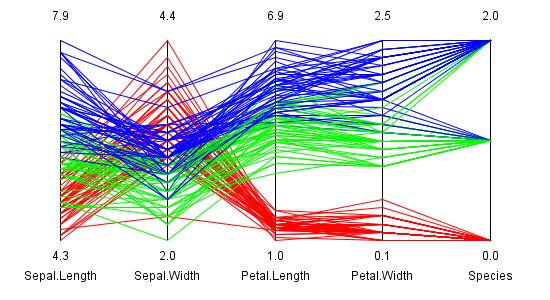
Abbildung 3: Clustering Ergebnis des Iris-Datensatzes dargestellt in Parallelen Koordinaten
In Abbildung 3 sind zunächst die vier Messdimensionen und als fünfte Dimension die Spezies zu
sehen. Die Datenpunkte wurden gemäß der Clusterzugehörigkeit eingefärbt. Man kann daraus erkennen, dass der
rote Cluster eine Spezies perfekt erkennt. Der blaue und der grüne Cluster teilen untereinander die beiden
"ähnlichsten" Spezies auf.
Durch die Selektion von Datenpunkten mit hoher Distanz zu deren Clusterzentren kann man nun Datenpunkte
identifizieren, die an den Rändern der Cluster liegen und somit wohl am ehesten der Clustereinteilung
widersprechen bzw. auch anderen Clustern zugeordnet werden können.
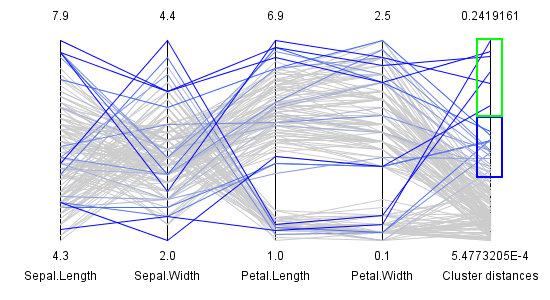
Abbildung 4: Selektion nach Clusterdistanzen
In Abbildung 4 sind zunächst wieder die vier Messdimensionen und als fünfte Dimension die Distanz der Datenpunkte zu deren Clusterzentren abgebildet. Durch die grüne Selektion werden Datenpunkte zu 100 % ausgewählt. Durch die darunterliegende blaue Selektion wird eine lineare Abschwächung der Auswahl (Degree of Interest - DOI) von 100% auf 0% durchgeführt.
| « Selektion in Linked Views | Mahalanobis und robuste Distanz » |